





In 2015, Raven estimated that 29% of the entire internet was duplicate content.
That’s billions of pages.
How could it be so much?
Because duplicate content is normal; there are perfectly good reasons why your website might have duplicate content within it and across domains.
Yet the SEO world has demonized duplicate content and fear-mongered many webmasters to believe any presence of duplicate content might warrant a Google penalty.
It won’t.
But duplicate content can cause issues for your SEO, like link dilution, fewer pages indexed, poorer rankings, and more.
So in this article, we’re going to explore the causes of duplicate content, the reasons why you should have duplicate content, and how canonicalization can prevent duplicate content from causing any issues for your search engine optimization.
Let’s go!
- What is duplicate content?
- Duplicate content vs. copyright infringement
- How much duplicate content is acceptable?
- Why is duplicate content bad for your SEO?
- Does Google penalize duplicate content?
- Tools to find duplicate content
- Common causes of duplicate content
- How to avoid duplicate content issues
- Wrapping up
Get brand new SEO strategies straight to your inbox every week. 23,739 people already are!Sign Me Up
What is duplicate content?
Duplicate content refers to content on your website that is “largely identical” to other content on your site or someone else’s site. Hence the name “duplicate.”
On-site duplicate content refers to content that is duplicated within your own domain, whereas off-site duplicate content refers to content that is duplicated across multiple domains (one of those domains being yours).
Duplicate content generall refers to substantive blocks of content within or across fomains that either complete match other content in the same language or are appreciably similar. Mostly, this is not deceoptive in origin. Examples of non-malicious duplicate content could include:
● Discussion forums that can generate both regular and stripped-down pages targeted at mobile devices
● Items in an online store that are shown or linked to by multiple distinct URLs
● Printer-only versions of web pages
Whether or not content was duplicated accidentally, intentionally, maliciously, or honestly, it’s still considered duplicate content.
And the internet is teeming with it.
Duplicate content vs. copyright infringement
Most duplicate content is not malicious or intentionally copyrighted; it’s typically your own content on your own site, duplicated on accident due to technical issues like URL parameters or server configuration.
However, duplicate content that also violates copyright laws happens all the time.
For example, if someone scrapes your content (or you scrape theirs) without permission or a license, that’s copyright infringement, obviously.
In fact, that happened to us. One agency literally ripped off our entire brand design and copy.

How much duplicate content is acceptable?
Do footer content, sidebars, or headers justify duplicate content since they appear on every page of your website?
No.
Google specifically states that duplicate content refers to “substantive blocks” of identical content, not boilerplate company info that helps aid website navigation or user experience.
Why is duplicate content bad for your SEO?
Aside from the rare penalty mentioned above, duplicate content can create a few issues for your SEO, namely:
- Less organic traffic
- Fewer indexed pages
- Dilution of backlinks
- Unfriendly SERP snippets
- Brand cannibalization
Fewer indexed pages
Though Google does a tremendous job of detecting the canonical (original) version of a duplicated page, there’s an outside chance that they may not index duplicated pages altogether, thus resulting in fewer indexed and rankable pages.
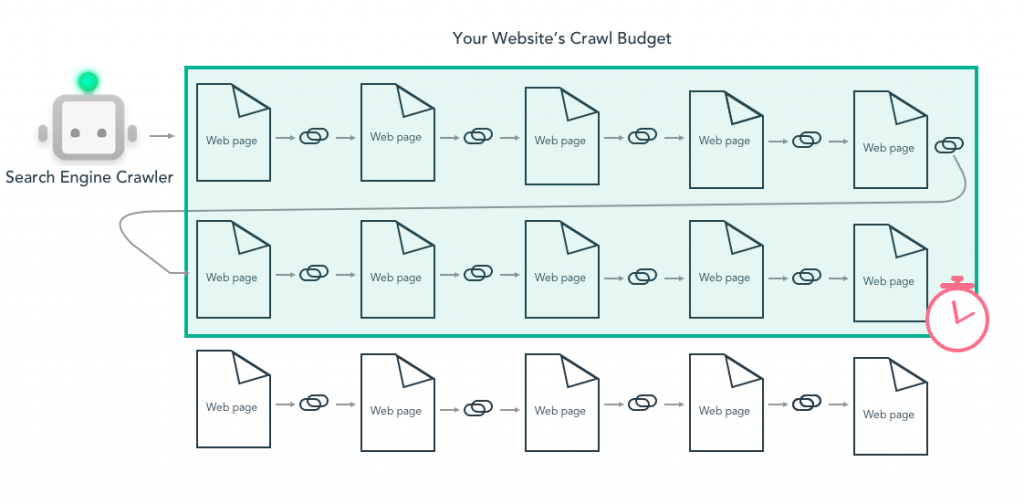
Also, for larger sites with hundreds of pages, if you make Googlebot work too hard crawling duplicate pages, you may exhaust your “crawl budget” (the amount of time web crawlers allot a specific site), delaying the crawling and indexing of unduplicated pages.
For example, you wouldn’t want to waste Googlebot’s time crawling a mobile, AMP and desktop version of the same page. Best to free up precious crawl budget so Google can index more pages.
Brand cannibalization
Have you ever heard of keyword cannibalization?
It’s when two different pages on your website with different but similar content (i.e. not duplicate content) compete for the same keywords. Thus, Google doesn’t know which page is most relevant for which query, so rankings suffer for both.
Well, brand cannibalization is similar. When it comes to duplicate content, if you post the same article on a third-party publisher like Medium or LinkedIn, or if someone scrapes your article and posts it on their blog, there’s a chance the third-party platform will outrank your page in SERPs.
And instead of you getting all the traffic, they do.
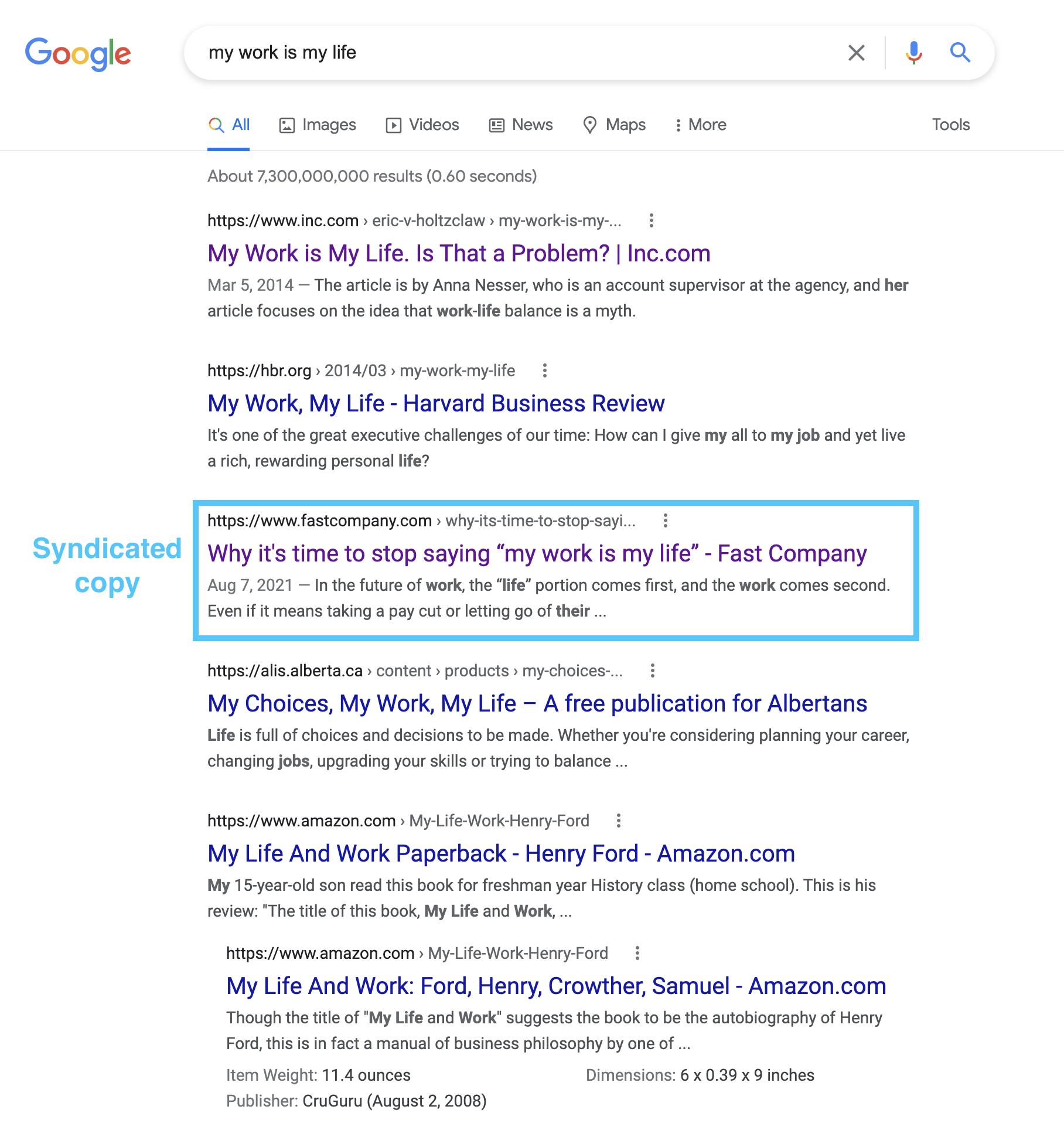
For example, FastCompany regularly syndicates articles from other publishers. Great for them, considering they have a massive readership. However, the publisher they syndicated from doesn’t rank for any relevant keywords. Not even the title of the article!
Backlink dilution
A backlink is a link to your site from another site, and Google’s algorithm views them as votes of confidence. The more links from high domain authority websites, the higher your rankings.
Simple.
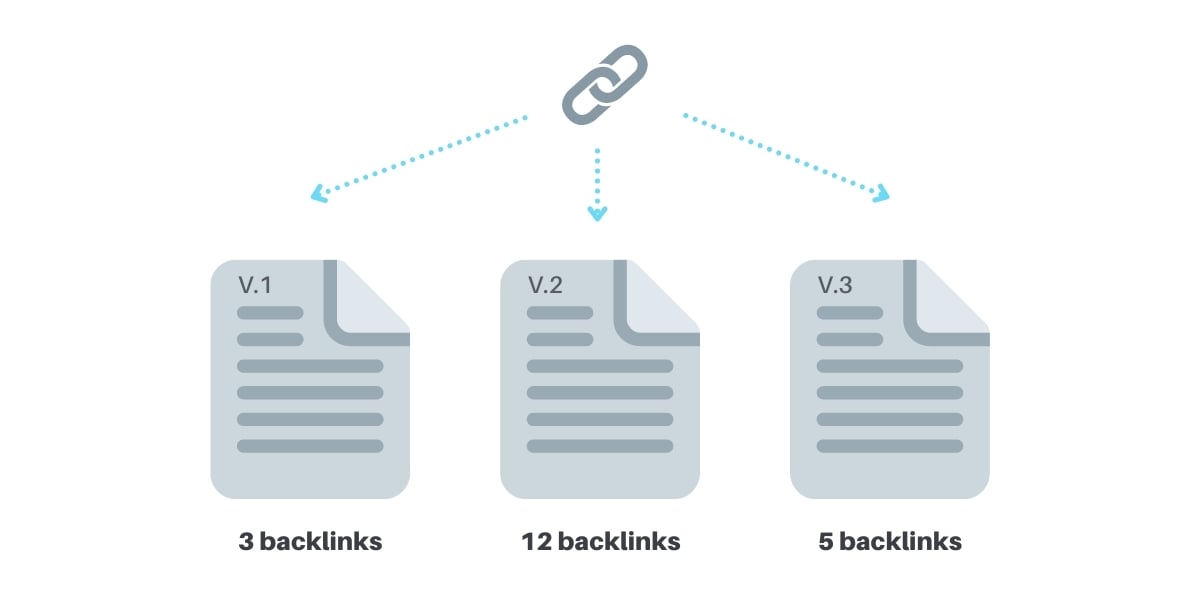
When you have multiple versions of the same page but on different URLs, you risk each page attracting its own backlinks.
The result?
Link equity gets divided unevenly between three versions of the page instead of going all towards the same page. And rankings suffer.
Less organic traffic
If another website ranks for your content, you lose that traffic, obviously.
But how else might duplicate content lead to a loss of organic search traffic?
Rankings.
When you force Google to make a decision about which version they should view as the original and which page to direct all link popularity toward, they may not know which page to select every time, thus throttling rankings for all versions of the page.

Unfriendly URLs
If Google detects multiple versions of the same page but with different URL parameters, they may show the long, unfriendly version in SERPs.
What’s a URL parameter? A parameter is a query string that gets added to the ends of URLs to help you track and filter information. Think eComm: many eCommerce sites use URL parameters when visitors filter results based on color, size, or price.

Which would you prefer Google shows in search results?
This:
Or this:
https://www.etsy.com/listing/695792680/resin-cow-skull-skull-animal-skull-cow
Data issues
If multiple versions of the same page rank and attract organic traffic, it makes it harder to analyze traffic data inside Google Analytics.
Does Google penalize duplicate content?
If Google web crawlers find duplicate content within your site or across domains, they don’t automatically penalize your website in the SERPs.
I repeat: There is no such thing as a duplicate content penalty (like a Penguin penalty or a Panda penalty) from Google or any other search engine.
Duplicate content on a site is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results. If your site suffers from duplicate content issues, and you don't follow the advice listed int his document, we do a good job of choosing a version of the content to show in search results.
Instead, they’ll try to identify which piece of content is the original version, then choose which version to rank.
However, in the event that Google determines you were maliciously duplicating content in an attempt to deceive search engines and rank more pages for the same content (thus creating a poor user experience for Google searchers), they reserve the right to adjust your rankings or remove you from their index entirely.
Google tries hard to index and show pages with distinct information. This filtering means, for instance, that if your site has a "regular" and "printer" version of each article, and neither of these is blocked with a noindex tag, we'll choose one of them to list. In the rare cases in which Google perceives that duplicate content may be shown with intent to manipulate our rankings and deceive our users, we'll also make appropriate adjustments in the indexing and ranking of the sites involved. As a result, the ranking of the site may suffer, or the site might be removed entirely from the Google index, in which case it will no longer appear in search results.
Tools to find duplicate content
Oddly enough, no great duplicate content checker exists. (If you know of one, let us know.)
SEO specialists have always relied on two tools: Siteliner and Copyscape.
Siteliner for duplication within your site. Copyscape for duplication across other domains.
Siteliner:
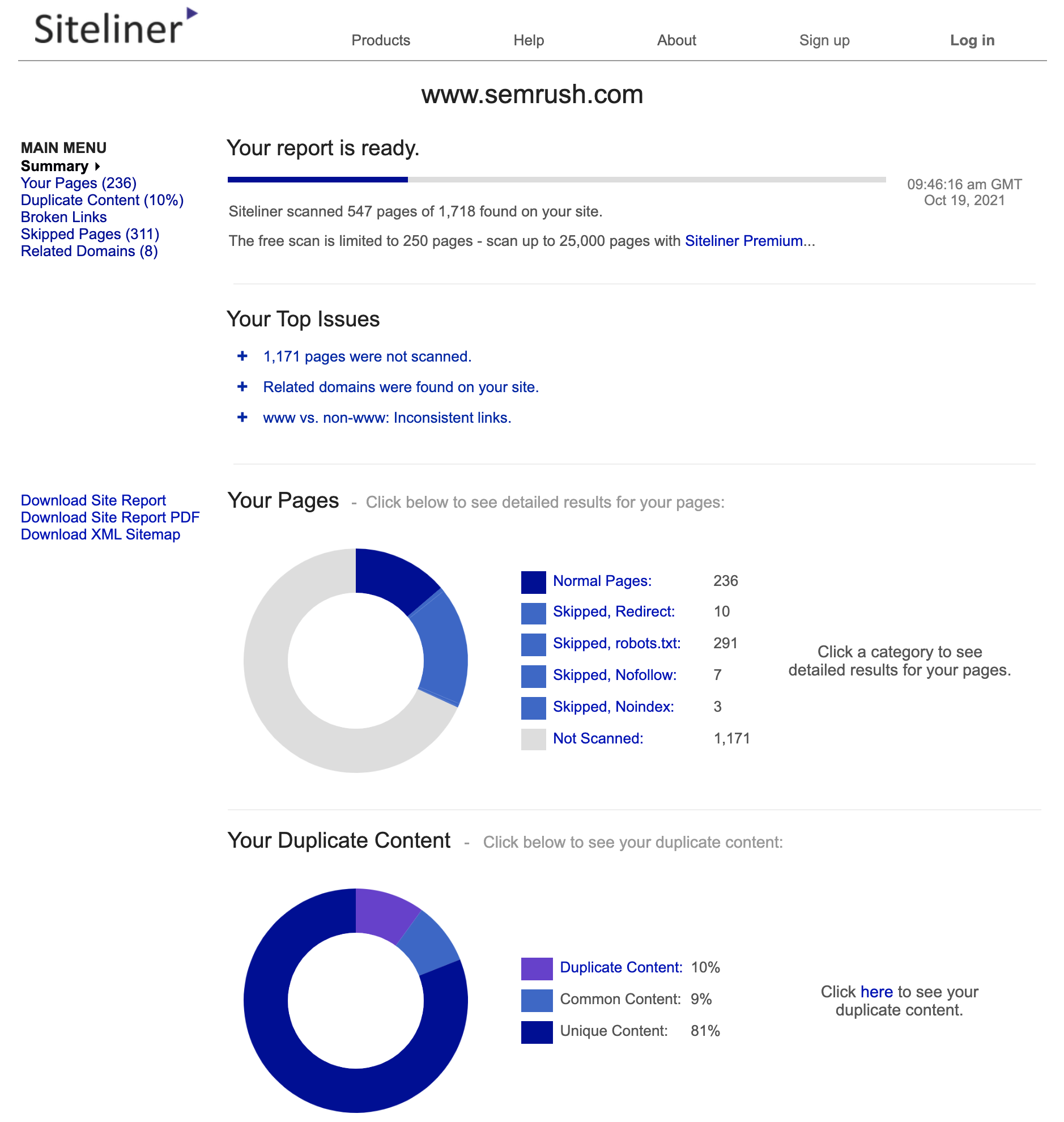
It’s not perfect: Siteliner picks up any content, including header, footer and non-critical content. So expect some duplicate content. However, you can still check pages they’ve marked as duplicate for yourself.
Copyscape:

Like Siteliner, Copyscape lets you input a URL, then checks for duplicate content across domains.
It used to be free, but if you want a full analysis, you need to pay for credits (starting at $10).
Using both tools in conjunction can help you find and analyze duplicate content faster (and should be a part of every SEO audit). And if you’re hiring freelance writers to publish on your website, enlisting a plagiarism tool wouldn’t help either.
Common causes of duplicate content
The truth: there are dozens of perfectly valid reasons why you should have duplicate content within your site or across domains.
Duplicate content problems rarely stem from malicious attacks.
Some of the most common (and normal) causes of duplicate content include:
- Multiple device types (mobile vs. desktop vs. amp vs. printer)
- Dynamic URLs (session IDs, tracking IDs, product filters)
- Server configuration (https vs. http; www vs. non-www; trailing slash vs. no slash)
- Content syndication
- Regional/language variants
- Staging sites
- Category/tag pages
- Pagination
Multiple device types
If you have a desktop, mobile, AMP, and printer-friendly version of your website, all on different URLs, that’s duplicate content.
For example:
- m.example.com/page
- example.com/page
- example.com/amp/page
- example.com/print/page
Dynamic URLs
If you use URL parameters like session IDs, tracking IDs, or filters, all can create duplicate versions on different URLs.
For example:
- Filter: example.com/paper?max_price=27&color=red
- Session ID: example.com/index.php?sid=123454321abcde-54321dcba
- Tracking ID: example.com/?utm_source=newsletter&utm_medium=email
Server configuration
Believe it or not, in Google’s eyes, the “www” version of your website is not the same as the “non-www” version, just like the “https” version is different than the “http’ version, and the trailing slash (.com/example/) is not the same as no slash (.com/example)
For example, there are technically all different:
- www.example.com
- example.com
- https://example.com
- http://example.com
- example.com/
- example.com
Content syndication
Content syndication is when one website or publisher licenses the work of another publisher, then republishes said work to their own website, or when you republish your own work (or a guest post) to a third-party publishing platform like Medium.com or LinkedIn.
Remember the FastCompany example? That’s content syndication.
FastCompany pays smaller publishers to license their articles, then reposts those articles to their own website. Same exact article (usually they alter the headline).

Regional/language variants
If you have an English, Spanish and Portuguese version of your website, all on different URLs, and all three versions are fully translated, that is not considered duplicate content. However, if you only translated the header, footer, and non-critical text, and left the main body of the content the same, that is considered duplicate content.
Different language versions of a single page are considered duplicates only if the main content is in the same language (that is, if only the header, footer, and other non-critical text is translated, but the body remains the same, then the pages are considered to be duplicates).
Staging sites
A staging site is a clone of your website that lives on a different URL. You use it to make web development edits before pushing them live to your main domain.
One problem: Though you should always discourage search engines from indexing a staging site (or use noindex/nofollow in your robots.txt), staging sites get accidentally indexed all the time.
Categories and tags
This one’s rare, but it happens.
In most cases, even if a content management system (CMS) like WordPress automatically creates category pages and tag pages, they won’t interfere with any blog posts ranking.
However, if a tag or category page only has one blog post, and that blog post is fully expanded when you land on the category/tag page, it’s essentially an exact duplicate of the original post, only on a different URL.
Boilerplate content
Boilerplate content is non-critical, stock content that gets reused in different contexts, but the words don’t change.
You can consider things like website navigation, blogrolls, sidebars, and footers boilerplate content.
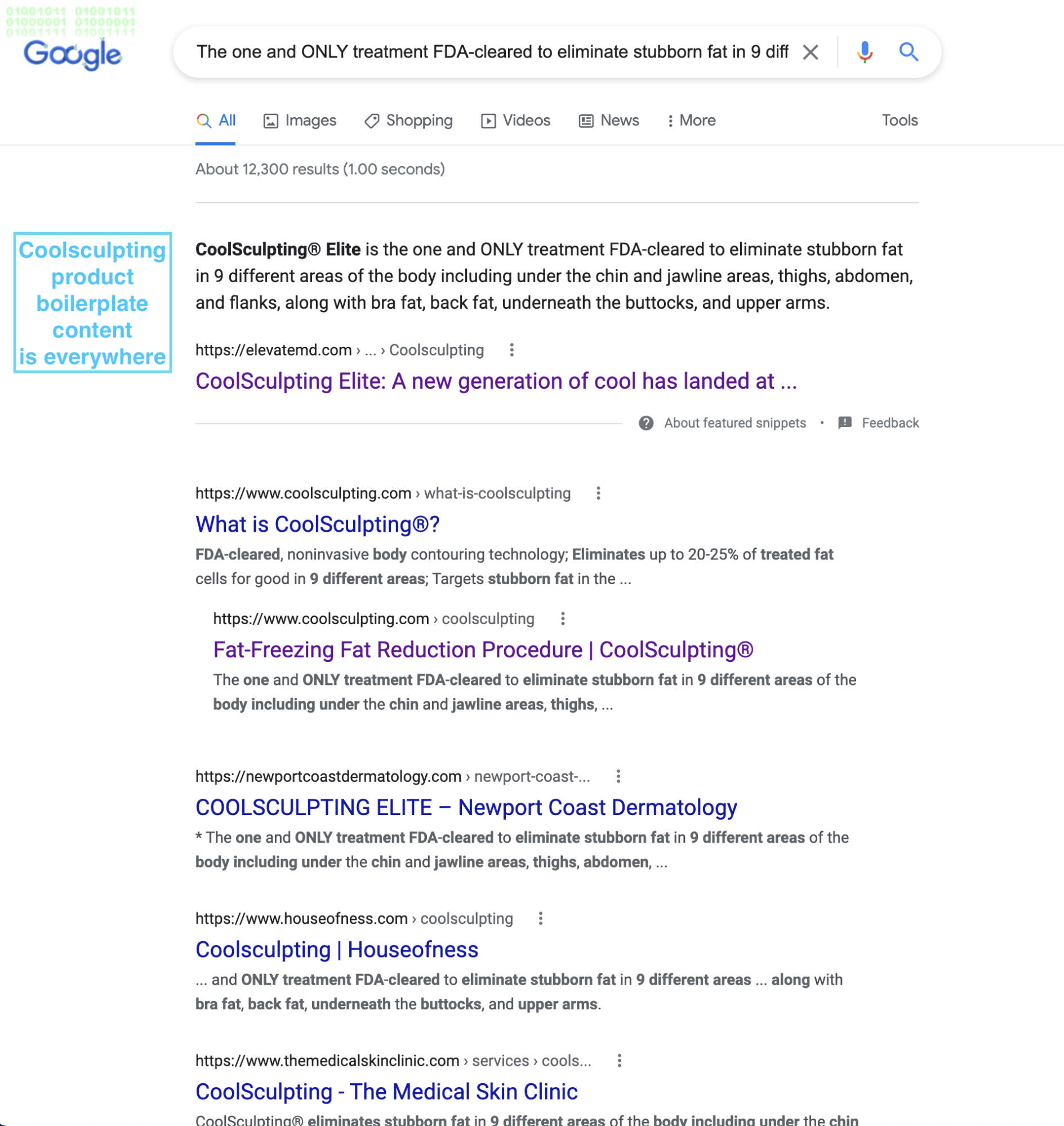
However, the boilerplate we’re talking about is product descriptions.
It’s common for dropshippers, product resellers, affiliates, and merchants to use manufacturer descriptions on their own sites.
Great for quick, easy product descriptions or landing pages.
Not so great if you want your product pages to rank in search.
For example, if a plastic surgeon wants to attract CoolSculpting patients through local search, they need original, unique content, not CoolSculpting stock descriptions.
How to avoid duplicate content issues
What if I told you that you could avoid duplicate content issues altogether with a simple 1-2 step method?
Well, it’s true.
It’s called canonicalization.
(Say that three times fast.)
Canonicalization tells search engines which version of a specific page is the original source.
Simple.
There are three primary methods you can use to canonicalize your pages, depending on the situation:
- Rel=canonical
- 301
- Sitemap
Rel=canonical link
By far the most common way to canonicalize a page is by placing a rel=canonical link tag in the header of the page.
We call it a “link” because it uses the href element (i.e. the same HTML element used for a hyperlink), but it doesn’t appear in the website copy; it only appears in the HTML/code.
A canonical link looks like this:
<link rel="canonical" href="https://example.com/page/" />
Where and when do you place a canonical link?
On every page of your website, and on any article that gets republished by a third party:
- Duplicated version: use rel=canonical to point to the original page.
- Original version: use the rel=canonical to point to itself. That way if your content gets scraped by web scrapers, the canonical tag will stay within the HTML.
- Syndicated version: use rel=canonical to point back to the original URL on your website. (Note: this doesn’t always prevent a higher domain authority website from outranking you).
- URL parameters: Use the canonical link to prevent duplicate content from URL parameters. But you can also tell Google to ignore URL parameters (not for beginners)
How do you implement a rel=canonical tag? All major CMSs have a feature or workaround for canonical URLs. Here are instructions for a few of the most popular:
- WordPress (via Yoast SEO Plugin)
- Wix
- SquareSpace
- Shopify
Note: Like a rel=canonical link, a rel=canonical header also names the original version, only for non-HTML pages like PDFs. See instructions from Google here.
301 permanent redirect
A 301 redirect is a status code that indicates to search engines that a page has moved to a different URL permanently.
For example, if you have three versions of a page on different URLs, you can put 301 redirects on two of those pages pointing back to the original version.
One caveat: unlike a rel=canonical link, a 301 redirect basically eliminates the other duplicates. Though they’ll still exist, when someone types in the URL (or when search engines visit), they’ll automatically get sent to the redirected page.
When should you use a 301 redirect?
For all the server configuration causes of duplicate content mentioned earlier:
- HTTP vs. HTTPS: HTTPS just means your site has an SSL certificate which makes it more secure. Hopefully you have one, because Google favors them in search results.
- WWW vs. non-WWW: it doesn’t matter which version you choose (we prefer non-www), just as long as the other version 301 redirects to it.
- Trailing slash vs. no slash: Again, it doesn’t matter which version you choose, just as long as the other version 301 redirects to it.
Note: You should also use Google Search Console (formerly Webmaster Tools) and Bing Webmaster Tools to specify which server configuration version you prefer.
Sitemap
A sitemap is a file that lists all the URLs on your site that you want indexed by search engines.
It looks like this:
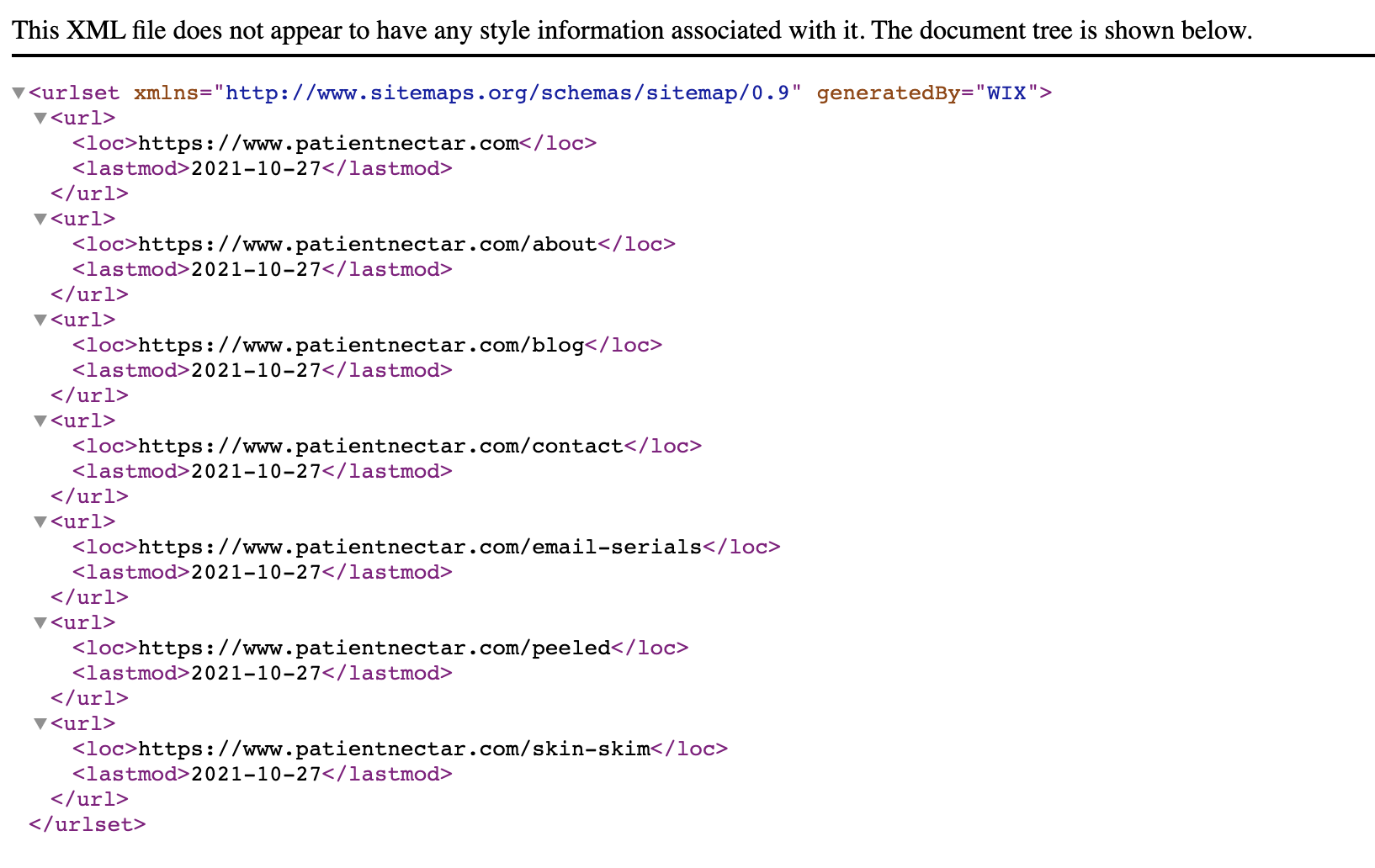
Think of a sitemap like a secondary discovery method for Google: just in case they miss a web page through your navigation or internal links, your sitemap will point it out.
As for canonicalization, you can use your sitemap to reference rel=canonicals too.
The same rules apply: under each URL submission within the sitemap, you would use the rel=canonical tag to specify the original version of the page.
Why do it this way? It makes it easier to canonicalize a large site. That’s all.
Want to learn more about creating sitemaps? We wrote an entire article about it here.
Note: To specify language variants with your sitemap, you can use the rel=hreflang attribute, just like you would the canonical. Google instructions here.
Wrapping up
Don’t walk in fear of duplicate content.
It happens. You can’t avoid it and it’s completely normal.
However, duplicate content issues like fewer indexed pages, less search traffic, poorer rankings, brand cannibalization and backlink dilution don’t have to happen.
Not if you properly canonicalize your pages.
Not if you produce original content.
And if someone scrapes your site or infringes on your copy, just sue them (call us, we know a guy).


